Intercepting Google CSE Resources: Automate Google Searches with Client-Side Generated URIs
by Renan de Lacerda Leite
Introduction
From an OSINT perspective, Google Search has been an indispensable tool for collecting data about companies, sites, persons, leaks, i.e, any kind of relevant information for countless investigation purposes.
Although mostly used by analysts on targeted research, there are actors who would take advantage of developing a fully automated discovery process using Google's Search Engine as one of its most important sources of data.
Nowadays, Google already offers to the public a service that facilitates the development of automated searches, which is called Google's Custom Search JSON API.
In order to use it, one needs to create its own Programmable Search Engine - a very useful Google service, created to help developers to embed Google search boxes in their websites, increasing their users experience by helping with more focused searches - and must ask for an API key to consume Google's JSON API.
However, this API has some free usage limits: after making a hundred (100) queries in a day, you'll be charged for a fee of five (5) American dollars per thousand (1000) queries - limited to ten thousand (10,000) queries a day if one does not want to use their restricted JSON API version - if you want to proceed with your automated data collection processes.
That's where this article comes in.
Exploring a client-side generated API Uniform Resource Identifier (URI), it was possible to consume Google's API data without needing to use any personal CSE API key and, consequently, without being charged for queries, as we avoid its traditional JSON API methods.
In order to consume this observed Google CSE API, a Python proof of concept module - named CSEHook - was developed, with the help of libraries such as Selenium Wire (a library that enables access to the underlying requests made by a browser) which was used to intercept Google CSE API URIs, Requests (a HTTP library) to consume the content of those previously intercepted URIs, and other publicly available resources.
Thought Process
Google's CSE, now called Google's Programmable Search Engine, is not news anymore.
Already well known by web developers who use it to embed Google search <iframes> in their site's pages, investigation actors who want to search predefined focused domains in order to collect particularly interesting data, and other kinds of individuals and professionals. This is a useful, widely spread public tool, first made to facilitate the embedding of Google search boxes in sites and the use of more specific, personalized, and focused search engines, but which happens to be an incredible tool for people who have a ton of research work to do.
Despite being truly helpful on its own, there are some things in its bundle that are not so handy for people who depend on heavy automated tasks to do its job: its CSE JSON API limits. For this reason, attempts to find alternative paths, for curiosity purposes, were made in order to contour those obstacles.
All the demonstrations were made with a personal Programmable Search Engine, focused on searching terms on Pastebin site pages.
Observing how the client-side of a Google CSE URI interacts with Google's back-end resources, a couple of interesting behaviors were noticed when a query is made:
- A request is sent to an ads URI (cse.google.com/cse_v2/ads), which responds with advertising content.
- A request is sent to an element's URI (cse.google.com/cse/element/v1), which responds with a text content containing a function call that takes a JSON object as an argument.
Even though the ads interactions could be consumed and parsed to some extent, what really calls the attention is the second behavior.
The figures below illustrate its response content:
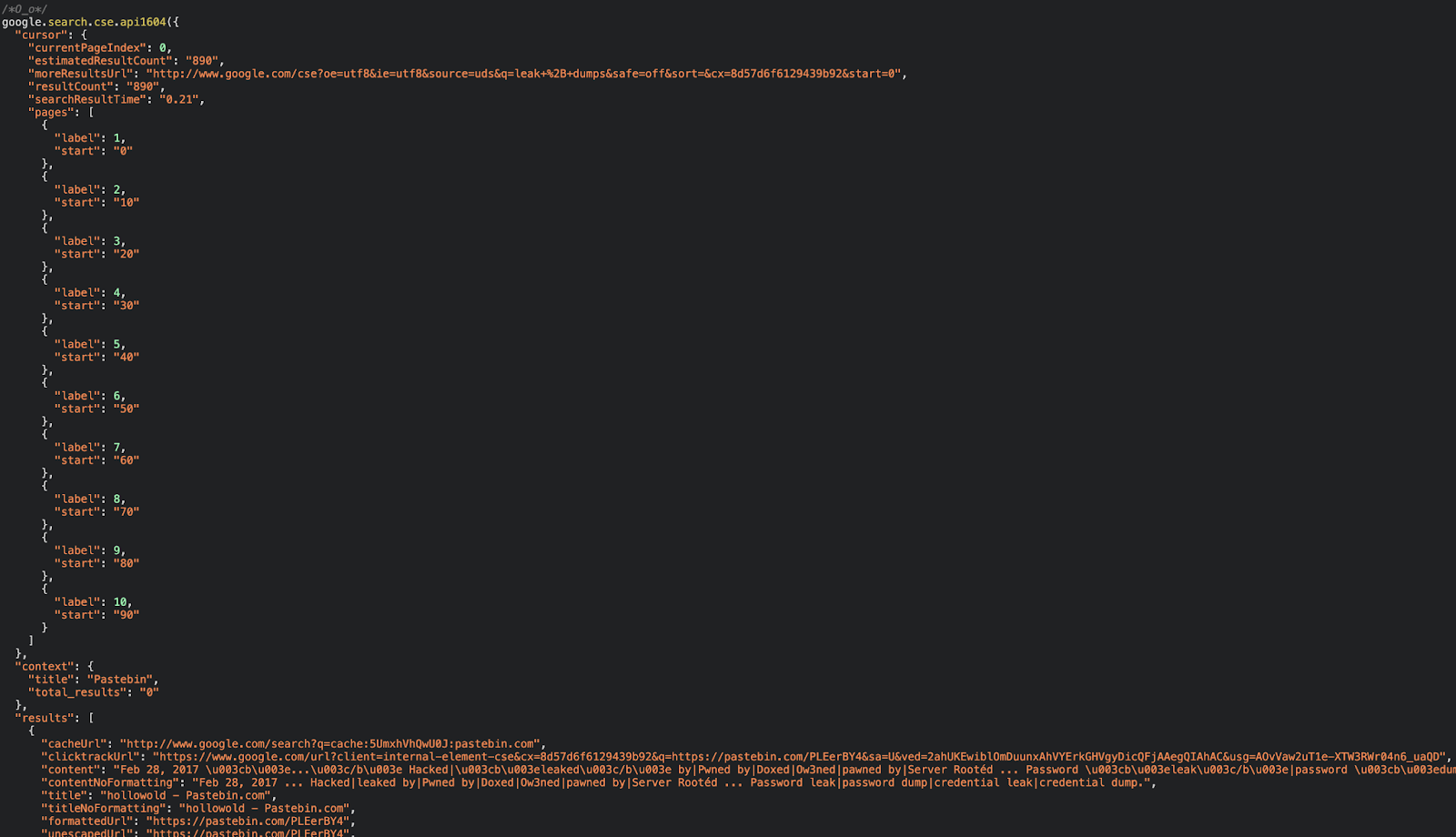
Beginning of client-side generated Element URI response.
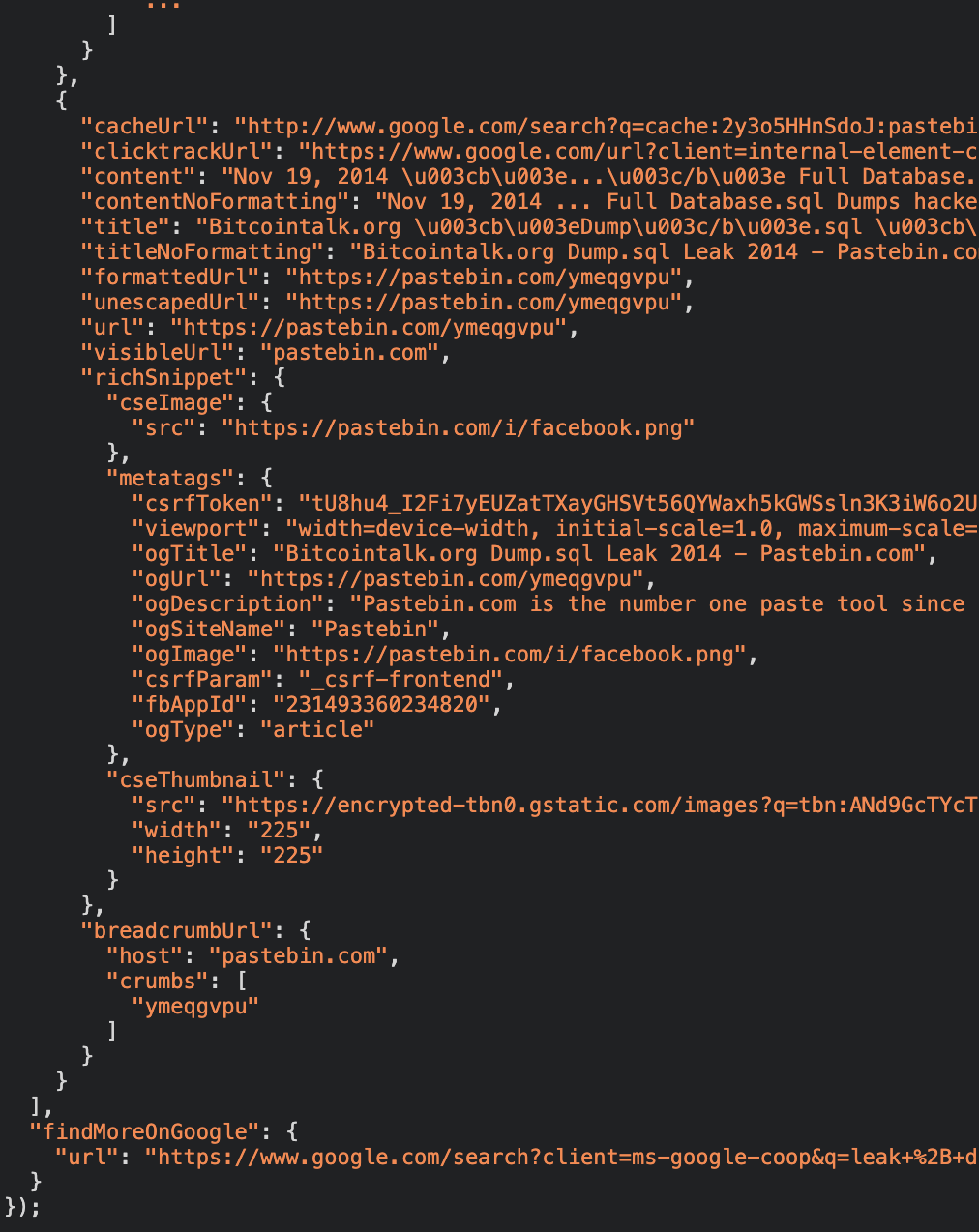
End of client-side generated Element URI response.
As illustrated, the response contains a call to a client-side JavaScript function, which receives a JSON object that was sent to the client from a Google server.
This function will parse the JSON object, which will always contain up to ten search results at a time (per page), up to ten maximum distinct pages, and exhibit the results in the CSE page that is being used.
Despite the front-end generating an individual URI for each performed query, what was noticed is that those URIs could be reused to query different terms, i.e there was a possibility to later automate the collection of data by intercepting the generated URIs, changing their query strings, and then requesting new results and parsing the collected content.
In order to achieve this, CSEHook was developed.
As the content to be consumed is a response of a dynamically-generated URI that depends on the execution of client-side JavaScript to be generated, it would be useful to use a browser instance in order to generate those interesting URIs.
The traditional Python solution to this kind of issues is generally Selenium; however, Selenium alone would not be able to track those client secondary network interactions that need to be intercepted. That is why the Selenium Wire, an extended version of Selenium that monitors the requests that were made by the browser instance, was chosen to help in the effort to catch those URIs.
A ChromeDriver will be needed so the Selenium Wire library can do its work. This driver should fit the installed Google Chrome browser version (used version: 91.0.4472.114 for x86_64).
Additionally, Geonode proxy service was used in order to avoid Google's detection systems and diffuse the requests made to its resources. This was implemented because, during the first implementation tests, it was observed that those URIs had a specific limitation to the amount of requests that could sequentially be sent to it. Apart from limiting the quantity of requests made to those dynamic URIs by re-intercepting those resources from time to time, it was preferred to spread the source IP addresses' geolocation that would be sending those requests as well.
Also, to avoid User-Agent pattern-based detections, a list of Google Chrome user agents was picked from tamimibrahim17's repository. This list was utilized in order to randomly choose a User-Agent and place it in the request headers to Google's resources.
Finally, to prove that it would be possible to surpass Google's official CSE JSON API limitations with the approach of this article, the Python library named English-Words was chosen so it could be demonstrated that the CSEHook proof-of-concept could effectively iterate through all set of English words in a relative short time, i.e., searching lowercase English words in order to obtain results from the already created Programmable Search Engine without calling Google's detection system's attention.
All the previously specified libraries and resources can be found in the References section. A link to their own respective websites was left there as well.
Proof-of-Concept Structure
To achieve the data collection intentions cited before, the project is structured in the following way:
- A config file, which contains some of the PoC configuration variables.
- A driver directory containing ChromeDrivers for Mac, Linux and Windows operating systems.
- A csehook directory, which contains the proof-of-concept necessary modules. Here are found a utility class - named WiredDriver, which interacts with Selenium Wire library and ChromeDrivers, and the main CseHook class which contains the main PoC code.
- A __main__ file, which has instantiations to the previously named classes and iterations through the English Words set in order to search those words with the intercepted Google's URIs.
- This structure can be better visualized at the project's GitHub repository.
Configuration
The configuration file has the following variables in it:
- CSE_URI, which is the URI of the previously created Programmable Search Engine.
- DEFAULT_DRIVER, which is the file path to the downloaded ChromeDriver.
- USER_AGENTS, which is an URI to the Chrome user agents of tamimibrahim17's project.
- RENEW_CSE_DEFAULT, which represents the amount of requests the application can do with the five intercepted Google client-side generated URIs. When the application reaches this limit, it will make more requests to the Programmable Search Engine URI in order to collect new client-side generated URIs. This is tunable, but Google will ban the main Programmable Search Engine URI searches if too many requests are made to the same client-side generated URIs, so this must be kept in mind before altering this configuration.
Example config.py file:
from os.path import join as os_join from pathlib import Path import requests CSE_URI = "{YOUR_CSE_URI_HERE}" # example: https://cse.google.com/cse?cx=... DEFAULT_DRIVER = os_join( Path(__file__).parent.resolve(), "driver/mac/chrome/chromedriver" ) USER_AGENTS = requests.get( "https://raw.githubusercontent.com/tamimibrahim17/" "List-of-user-agents/master/Chrome.txt" ).text.split('\n')[3:] RENEW_CSE_DEFAULT = 38 |
Wired Driver
This is the class that interacts with the Selenium Wire library.
Not too much to detail: an instance of this class will be used in order to interact with the Google Chrome browser so it can be possible to intercept the client-side generated URIs. The file structure is illustrated by the image below.
Class WireDriver that generates the browser instance and handles options:
from urllib.parse import urlparse from selenium.webdriver.chrome.options import Options from seleniumwire import webdriver from config import DEFAULT_DRIVER class WiredDriver: def __init__(self, path: str = DEFAULT_DRIVER, headless: bool = True, proxy: str = str()): self._options = Options() self._options.headless = headless self._seleniumwire_options = {} if proxy: proxy = urlparse(proxy) _host = proxy.hostname if proxy.port: _host = f"{_host}:{proxy.port}" self._seleniumwire_options["proxy"] = { "http": f"http://{_host}", "https": f"https://{_host}", "no_proxy": "localhost,127.0.0.1" } self.instance = webdriver.Chrome( path, options=self._options, seleniumwire_options=self._seleniumwire_options ) |
CSE Hook
Here is where the main logic is placed.
It's explanation will be broken in different fragments in order to detail it's functionality.
The class has three internal inherent attributes that do not depend on its initialization:
- _MAX_PROXY_RETRIES - Which establishes the amount of request reattempts it could make with the in-memory previously downloaded proxies before requesting for new ones to Geonode.
- _STANDARD_SLEEP - Which is just the amount of seconds it would keep sleeping if, and only if, Google expires the client-side generated URIs before the applications renews it, which would be an unexpected behavior.
- _TIMEOUT - That is just the amount of time the Requests library should wait for a response while requesting with proxies.
Inside the class initialized components, there are the following attributes:
- self._amount_of_words - Which specified the amount of words to be queried to the main Programmable Search Engine in order to collect the same amount of client-side generated URIs, i.e., if it searches for five words - which is it's default value - it will search the main URI five times and intercept five different client-side generated URIs.
- self._word_size - Which is the amount of characters each randomly generated searched word would have in order to obtain the client-side generated URIs.
- self._cse_uri - Which represents the Programmable Search Engine URI that will be used so it can intercept the client-side generated URIs.
- self._is_cse_uri_valid - Which checks if the specified URI is a valid Programmable Search Engine URI.
- self._wired_driver - Which just saves the specified wired_driver instance.
- self._cse_api_pattern - Which is a pattern for the first URI characters of the targeted client-side generated URIs so it can identify those URIs in the intercepted URIs list of the Selenium Wire instance.
- self._cse_regex - Which is a regex that will form the groups necessary in order to catch the JSON inside the JavaScript function call of the client-side generated URI response.
- self._cse_api_uris - Which is an empty list that will contain the client-side generated URIs intercepted by the code.
- self._pages - Which just maps the page labels with its start required offset.
- self._proxy_list - Which receives the results of self._config_proxy_list, a method that is responsible for requesting Geonode for new proxies.
CseHook class pre-initialization and initialized attributes:
class CseHook: _MAX_PROXY_RETRIES = 50 _STANDARD_SLEEP = 10 _TIMEOUT = 8 def __init__(self, cse_uri: str, wired_driver: WiredDriver, word_size: int = 5): self._amount_of_words: int = word_size self._word_size: int = word_size self._cse_uri = urlparse(cse_uri) _is_cse_uri_valid: bool = any([ self._cse_uri.query.startswith("cx="), self._cse_uri.hostname.startswith("cse.google.com") ]) if not _is_cse_uri_valid: raise AttributeError("An invalid Google CSE URI was specified.") self._wired_driver: WiredDriver = wired_driver if not isinstance(self._wired_driver, WiredDriver): raise AttributeError("Specify a valid WiredDriver instance.") self._cse_api_pattern: str = "https://cse.google.com/cse/element/" self._cse_regex = re.compile( r"(?<=google[.]search[.]cse[.]api)" r"([0-9]*\()" r"((.|\n|[{}]|)*)(?=\))" ) self._cse_api_uris: list = [] self._pages = { label: start for label, start in zip(range(1, 11), range(0, 91, 10)) } self._proxy_list = self._config_proxy_list() ... |
The next four methods listed inside the class are responsible for the following activities:
- The method self._get_modified_uri is responsible for parsing the received URI and returning a string which is a modified version of the same URI. The query parameters q (query) and start (start offset/page) are the ones that are changed by this method.
- The method self._config_proxy_list is responsible for requesting Geonode for new proxies. It will return the list of data offered by Geonode's endpoint.
- The method self._get_random_words is responsible for yielding randomly generated words on demand, based on the previously defined attributes self._word_size and self._amount_of_words.
- The method self._config_new_cse_api_uris is responsible for configuring the intercepted client-side generated URIs. It will: iterate through the words yielded by self._get_random_words; modify the Programmable Search Engine URI using self._get_modified_uri in order to place the word in the q query parameter; use the modified Programmable Search Engine URI to query a word just to intercept and collect the client-generated URI; append the found client-generated URI to the self._cse_api_uris list.
The first four methods present in CseHook class:
def _get_modified_uri(self, uri: str, query: str, page: int = 1) -> str: # Parse URL, modify it and return its requestable resource. parsed_uri = urlparse(uri) base_uri = ( f"{parsed_uri.scheme}://{parsed_uri.hostname}{parsed_uri.path}" ) parsed_query = parse_qs(parsed_uri.query) parsed_query['q'] = [query] if page > 1: parsed_query["start"] = [self._pages.get(page)] query_string = '&'.join( f"{k}={v[0]}" for k, v in parsed_query.items() ) return f"{base_uri}?{query_string}" @staticmethod def _config_proxy_list() -> list: response = requests.get( "https://proxylist.geonode.com/api/proxy-list?" "limit=100&page=1&sort_by=lastChecked&sort_type=desc" "&speed=fast" ) return response.json().get("data") def _get_random_words(self) -> Iterator[str]: # Yield random words based on word_size and amount_of_words. yield from ( ''.join(random.choice(_alphabet) for _ in range(self._word_size)) for _ in range(self._amount_of_words) ) def _config_new_cse_api_uris(self) -> None: # Configures new CSE API URIs to be used. self._cse_api_uris = [] for query in self._get_random_words(): uri = self._get_modified_uri(self._cse_uri.geturl(), query) self._wired_driver.instance.get(uri) wired_requests = ( request.url for request in self._wired_driver.instance.requests ) self._cse_api_uris.append(next(filter( lambda req: req.startswith(self._cse_api_pattern), wired_requests ))) del self._wired_driver.instance.requests ... |
The fifth method is called self._get_response, and its responsibility is to request an endpoint using the specified URI, headers and proxies. If the request raises a timeout or any other exception, it will check if the amount of retries - which is passed as an argument as well - has achieved its limit. If this limit is achieved, it configures self._proxy_list with a new proxy list retrieved from Geonode.
The fifth method present in CseHook class:
def _get_response(self, uri: str, headers: dict, proxies: dict, retries: int = 0) -> Union[requests.Response, bool]: # Attempt to request with specified params. # # Returns: # bool -- when a request raised an exception. # requests.Response -- when endpoint was requested successfully. # with suppress(Exception): response = requests.get( uri, headers=headers, proxies=proxies, timeout=self._TIMEOUT ) return response if retries >= self._MAX_PROXY_RETRIES: self._proxy_list = self._config_proxy_list() return False ... |
The sixth method is named self._search_page.
This method receives the arguments URI, query and page and returns the JSON retrieved from the modified client-side generated URI response, i.e., the results from Google that it wants to collect with a specific query term.
This is the most complex method of the class, and what interacts with most of the other already declared methods.
While the response is not received from Google, it will: select a random User-Agent and define it in the request headers; choose a random proxy from the self._proxy_list; form the proxies dictionary with the information of the chosen_proxy so it can be used with the Requests library; get a response using the method self._get_response; if the response is not satisfactory, it will pop the chosen_proxy from the self._proxy_list and increase the error_count by one and will continue the loop. The error_count is the value passed as the argument retries of the self._get_response method.
If the response is received, check if the status_code of the response equals 403 (HTTPStatus.FORBIDDEN). If it does, return a dictionary with the key-value pair illustrated by the following image. If it does not, find the JSON inside the client-side generated URI response with the self._cse_regex compiled regex, catch it and assign it to api_json.
After assigning, return api_ json.
The sixth method present in CseHook class:
def _search_page(self, uri: str, query: str, page: int = 1) -> Union[_GoogleCSEJson, dict]: # Request a CSE API and return its json. schemas = ("http", "https") error_count = 0 response = False # Retries different proxies until we have a response. while not response: headers = {"User-Agent": random.choice(USER_AGENTS)} if not self._proxy_list: self._proxy_list = self._config_proxy_list() chosen_proxy = random.choice(self._proxy_list) protocol = chosen_proxy.get('protocols')[0] ip = chosen_proxy.get("ip") port = chosen_proxy.get("port") proxies = {k: f"{protocol}://{ip}:{port}" for k in schemas} response = self._get_response( self._get_modified_uri(uri, query, page), headers=headers, proxies=proxies, retries=error_count ) # Remove bad proxy from list. if not response: self._proxy_list.pop(self._proxy_list.index(chosen_proxy)) error_count += 1 # Avoid too many requests to Geonode. # Sometimes proxies are just bad in that moment. if error_count > self._MAX_PROXY_RETRIES: error_count = 0 status_code = response.status_code if status_code == HTTPStatus.FORBIDDEN: return {"error": "temp_ban"} api_json = json.loads(self._cse_regex.findall(response.text)[0][1]) return api_json ... |
The last method of the class is named self.search, which is the only public method of the class - and the one that is used by __main__.
This method receives both query, the term that one wants to search using the client-side generated URIs, and renew_cse_uris, which is a Boolean that determines if the client-side generated URIs should be refreshed as arguments.
The responsibilities of this method are the following:
- Quote the received query string so it can be correctly placed in the client-side generated URIs.
- If the self._cse_api_uris list still has no client-side generated URIs or if it is explicitly told to renew them, execute self._config_new_cse_api_uris so it can configure new intercepted client-side generated URIs.
- Request the first page using the self._search_page method. The arguments passed to self._search_page will be a client-side generated URI randomly picked from the self._cse_api_uris list and a quoted query string.
- If the first page already returns an error key, it can mean two things: the Programmable Search Engine URI was temporarily banned or, the client-side generated URIs got old and need to be renewed. If the main Programmable Search Engine URI was temporarily banned, return False and pause execution. If the client-side generated URI just got old, renew them and request for another first_page.
- If the cursor returned by the first page says that only one page is available, return an iterator with the results of the first page; if there are more pages to iterate through, proceed with execution and yield the iterator with the first page results plus an iterator with the results for the next pages - only if they return more results.
All this logic flow can be better visualized by looking at the following image.
The last method of the CseHook class:
def search(self, query: str, renew_cse_uris: bool = False) -> _GoogleCSEIterator: # Get Google CSE results using our CSE API URIs. # # Return: an iterable object with all available Google CSE pages. # query = quote(str(query)) if not self._cse_api_uris or renew_cse_uris: self._config_new_cse_api_uris() first_page = self._search_page( random.choice(self._cse_api_uris), query ) error = first_page.get("error") while error: # If we were temporarily banned, return False. if isinstance(error, str): return False # If old CSE API URIs start to fail, refresh them. sleep(self._STANDARD_SLEEP) self._config_new_cse_api_uris() first_page = self._search_page( random.choice(self._cse_api_uris), query ) first_result = iter((first_page.get("results", []),)) if len(first_page.get("cursor", {}).get("pages", [])) <= 1: return first_result # If more then one page available, yield them all on-demand. yield from chain( first_result, ( results for p in tuple(self._pages.keys())[1:] if ( results := self._search_page( random.choice(self._cse_api_uris), query, p ).get("results", []) ) ) ) |
Now that all the attributes and methods of CseHook were detailed, there is only __main__ left to explain.
Main
The __main__ file contains the instantiations made to WiredDriver and CseHook, along with a few more things.
The following activities are present in this file:
- A WiredDriver instance is created.
- An amount_of_requests counter is initialized as zero (0). This will serve to count the amount of requests made to client-side generated URIs and to exhibit the number at the terminal, so the amount of requests can be monitored without needing to store all the results locally.
- A CseHook instance is created by specifying a previously created Programmable Search Engine URI and a WiredDriver created instance.
- A list containing the English words in lowercase is initialized and shuffled afterwards.
- A requests_to_reload_cse_uris counter is initialized with the RENEW_CSE_DEFAULT (38) configuration value. This will serve as a negative counter so it can ask the CseHook.search method to renew the client-side generated URIs (intercept new ones and save them in a class list).
- Like cited previously, if the requests_to_reload_cse_uris count reaches zero, renew the client-side generated URIs and set requests_to_reload_cse_uri to RENEW_CSE_DEFAULT again. If it is still bigger than zero, proceed requesting with the already intercepted client-side generated URIs.
- If the returned pages_results is False, break the execution because the Programmable Search Engine was temporarily banned. If it is an iterator, proceed with iterations.
- For each iteration made through pages_results - i.e., for each requested page, print the page results, sum one to amount_of_requests and print the variable value. Next, after requesting a page, subtract one from requests_to_reload_cse_uris.
- When the code is interrupted, print its final amount_of_requests number.
The details can be better visualized by looking at the following image.
__main__ file content:
from random import randint, shuffle from time import sleep from english_words import english_words_lower_set from config import CSE_URI, RENEW_CSE_DEFAULT from csehook import CseHook, WiredDriver if __name__ == "__main__": wired_driver = WiredDriver() amount_of_requests = 0 try: cse_hook = CseHook(CSE_URI, wired_driver) english_words_list = list(english_words_lower_set) shuffle(english_words_list) # When reaches 0, its time to renew client-side URIs. requests_to_reload_cse_uris = RENEW_CSE_DEFAULT for word in english_words_list: if requests_to_reload_cse_uris <= 0: pages_results = cse_hook.search(word, renew_cse_uris=True) requests_to_reload_cse_uris = RENEW_CSE_DEFAULT else: pages_results = cse_hook.search(word) # It returns bool (False) if temporary ban was imposed. if isinstance(pages_results, bool) and not pages_results: break for results in pages_results: print(results) amount_of_requests += 1 print(amount_of_requests) requests_to_reload_cse_uris -= 1 finally: print(f"Number of requests: {amount_of_requests}") wired_driver.instance.close() |
Obtained Results
To prove that this intercepted client-side generated URIs could be explored in a large scale, the code was left running for 24 hours to see how many requests could be made, without interruptions or banishments, within that time frame.
Surprisingly enough, even though Geonode proxies were used - and a lot of them were not even functioning correctly, which delayed the amount of iterations/requests that could be made in the same time frame without these obstacles - *15,706 requests were made to Google resources, all of them containing real and valid Google results just before the execution was interrupted.
It means that the PoC would iterate through all the lowercase English words in less than two days - given that the set has 25,480 words in it.
The following image illustrates it (zoom it in order to see them better):

It also means that it has surpassed the daily quota limits (10,000 a day maximum) allowed by the official Google CSE JSON API - the one without Restricted JSON - by a lot, and surpassed even more the Google CSE JSON API free usage limits (100 a day maximum).
Conclusion
The PoC demonstrated that, within a time frame of 24 hours, 15,706 requests were made and successfully returned Google CSE page values using the intercepted client-side generated URIs as a facilitator, in order to obtain JSON format results.
With basic user-agent randomization, client-side generated URIs frequent renewal and proxy changes, one could avoid Google's detection mechanisms and consume its data without the need to subscribe for it's JSON CSE API fees.
References
- Selenium Wire: pypi.org/project/selenium-wire
- Requests: docs.python-requests.org/en/master
- User-Agents: github.com/tamimibrahim17/List-of-user-agents/blob/master/Chrome.txt
- Geonode Proxies: geonode.com/free-proxy-list
- Google CSE: programmablesearchengine.google.com/about
- English-Words: pypi.org/project/english-words
- Regex101: regex101.com
- Custom Search JSON API rules: developers.google.com/custom-search/v1/overview
- CSEHook: github.com/basyron/csehook